배경
최근에 토이 프로젝트에서 위치 기반 서비스에 대한 관심이 증가하고 있다.
우아한테크코스 5기만 하더라도 진행된 24개 프로젝트 중 7개 팀이
위치(좌표)를 기반으로 한 데이터 정리 기능을 포함하고 있었다.
이 글은 괜찮을지도 프로젝트를 수행하는 과정(혹은 그 이후에)에서,
위치 기반 서비스에 관련된 지식을 배우면서 알게 된 유용한 정보 중
사전에 알고 있었다면 도움이 됐을 내용들을 정리한 것이다.
다른 개발자들, 또는 미래의 나 자신이 위치 기반 서비스를 다룰 때
이 글을 통해 도움을 받기를 바란다.
위치 기반 서비스에서 백엔드는 무엇을 신경써야할까?
백엔드는 웹 개발 중 사용자가 요구하는 정보를 저장, 관리, 그리고 제공하는 역할을 수행한다.
위치 기반 서비스의 경우엔, 사용자가 요구하는 정보가 주로 위치 데이터가 될 것이다.
사용자가 특정 위치 데이터를 요청할 때, 해당 데이터를 효과적으로 제공하기 위해선
위치 기반 서비스의 백엔드는 지역별 혹은 거리(반경) 내 데이터 조회를 고려해야한다.
예를 들어, 사용자가 선릉역을 조회하는 경우를 생각해보자.
삼성동에 위치한 역들 중에서 선릉역을 찾는 경우 (지역별 조회) 와
선릉과 정릉의 반경 500m 이내에 위치한 역들 중 선릉역을 찾는 경우 (반경 내 조회) 가 있을 것이다.
이렇듯 사용자가 어떤 조건에서 위치 데이터를 조회하든,
모두 대응할 수 있도록 데이터베이스 테이블을 잘 설계하는 것이 중요하다.
지역별 조회: 행정동과 법정동의 이해
지역별로 조회하기 위해서는 각 지역을 분류하기위한 체계가 필요하다.
우리나라에서는 지리 관리를 행정동과 법정동 두 가지 유형으로 구분하여 관리하고 있다.
- 행정동: 행정 운영의 효율성과 주민 편의를 위해 설정된 행정 구역으로, 행정 기관이 관할하는 단위다.
- 법정동: 등기소 등 공공기관에서 사용하는 공식 법정 주소로, 법률에 의해 정해진 구역이다.
행정동과 법정동을 식별하는 코드 구조는 다음과 같다
- 코드 구성: 12(시도) + 345(시군구) + 678(읍면동) + 90(리)
이 코드는 10자리로 구성되며, 시도, 시군구, 읍면까지의 구분에서는 행정동 코드와 법정동 코드가 동일하다.
하지만 동리 단위에서부터 두 코드가 다르게 분류된다.
그렇다면 두 코드 중 무엇을 기준으로 지역을 분류하여야할까?
행정동 코드는 행정 구역 변화에 따라 자주 변경될 수 있으며,
이는 내부 관리 시스템과 실제 행정동 간의 불일치를 초래할 수 있다.
반면 법정동은 1914년 시행된 행정구역 통폐합 이후로 변동이 거의 발생하지 않았다.
추가적으로 법정동은 행정동에서 구분하지 않는 리를 구분하므로,
행정동에 비해 더 세밀한 데이터 분류가 가능하다는 장점이 있다.
이런 이유에서, 지리 정보를 관리할 때는 변동성이 낮고 세밀한 분류가 가능한
법정동코드를 사용하는 것을 추천한다.
법정동 코드를 데이터베이스 스키마에 포함시키고 인덱싱을 적용함으로써,
지역별 조회 성능을 최적화할 수 있다.
SQL에서 LIKE 연산을 사용할 때, 검색어의 뒷부분에 %를 사용하면
전방 일치 검색에서 인덱스를 탐색할 수 있게 하므로, 검색 효율이 개선된다.
시도 단위의 코드를 Enum이나 별도의 참조 테이블로 관리한다면,
LIKE 연산을 사용한 검색어의 길이를 통해 시도, 시군구, 읍면동, 리 수준까지 세분화하여
인덱스를 활용한 조회가 가능하다.
반경 내 조회: 위도와 경도의 이해
반경 내에서 조회하기 위해서는 특정 위치를 표현하기 위한 좌표가 필요하다.
위도와 경도는 지구상의 위치를 정확하게 표현하기 위해 사용되는 좌표 체계다.
위경도 좌표 체계는 지구가 완벽한 구형이 아닌 형태를 가지고 있기 때문에 다양한 형태로 존재할 수 있다.
해당 글에서는 GPS에 사용되는 WGS84 좌표 체계를 기준으로 설명한다.
- 위도(Latitude): 적도를 기준으로 북위 또는 남위 0도에서 90도 범위로 표현된다.
- 경도(Longitude): 본초 자오선을 기준으로 동경 또는 서경 0도에서 180도 범위로 표현된다.
그렇다면 위도와 경도는 소수점 몇째자리까지 저장을 해야할까?
위도와 경도를 얼마나 정밀하게 저장해야 할지는
서비스에서 요구하는 거리 오차의 허용 범위에 따라 달라진다.
건물 단위로 위치를 식별하는 경우, 미터 단위의 정밀도로도 충분할 수 있다.
그러나 더 높은 정밀도를 위하여 센티미터 단위까지 구분한다고 가정하자.
- 위도 간의 거리: 약 111킬로미터(1킬로미터 오차 범위 내)로 일정하다.
- 경도 간의 거리: 위도에 따라 크게 달라지며, 경도 간의 거리가 가장 긴 적도 부근에서는 약 111.320킬로미터이다.
이를 통해, 약 1.1센티미터의 정밀도를 표현하기 위해선
위도와 경도의 소수점 일곱 번째 자리까지 저장해야한다는 결론을 얻을 수 있다.
데이터 타입: 부동소수점의 이해
일반적으로 자리수가 큰 소수를 코드 내에서 표현하기 위해서는double 혹은 BigDecimal을 이용하여 값을 저장한다.
그렇다면 위도와 경도는 어떤 자료형으로 저장을 해야할까?
대한민국 한반도는 위도 북위 33 ~ 43, 경도 동경 124 ~ 132 사이에 위치한다.
그리고 센티미터 단위의 정밀도를 표현하기 위해서 소수점 일곱 번째 자리까지 저장해야한다.
즉, 정수 부분을 포함하여 총 10자리 수(정수 3자리 + 소수점 7자리)를 저장 해야 함을 의미한다.
10자리의 소수를 저장할 때, 자료형에 따른 성능 비교 실험을 진행하였다.

약 2만건의 데이터를 저장하였을 때,
double: 속도- 694ms / 메모리 사용량 - 12.47mb
BigDecimal: 속도- 721ms / 메모리 사용량 - 13.76mb
약 30만건의 데이터를 저장하였을 때,
double: 속도- 1667ms / 메모리 사용량 - 155.75mb
BigDecimal: 속도- 1804ms / 메모리 사용량 - 173.86mb
실험 진행 결과, double이 속도와 메모리 사용량 모두에서 더 효율적이었다.
double은 연산자를 직접 사용할 수 있어 사용성에서도 BigDecimal보다 우위에 있었다.

단, 총 15~16자리 이상의 수를 다뤄야할 경우, 반드시 BigDecimal을 사용해야한다.
double은 반올림을 수행하기 때문에, 값에 오차가 발생하고
속도에서도 BigDecimal에 비해 비효율적이기 때문이다.
이러한 분석을 바탕으로, 위도와 경도 값의 총 자리수가 15자리 미만인 경우,
double로 저장하는 것이 성능적으로 유리하고, 사용성 측면에서도 편리하다는 결론을 도출할 수 있다.
하버사인 공식과 공간 인덱스
선릉역 주변 100km 이내에 무작위로 생성한 100만건의 좌표 데이터를 Location 테이블에 저장하였다.
이를 조회하기 위해 두 가지 SQL 방법을 고려했다.
첫 번째는 삼각 함수를 활용한 하버사인 공식을 구현한 SQL이고,
두 번째는 공간 인덱스(ST_Buffer와 ST_CONTAINS)를 활용한 SQL이다.
하버사인 공식 SQL
SELECT * FROM Location AS l
WHERE (6371000 * acos(cos(radians(:latitude))
* cos(radians(l.latitude))
* cos(radians(l.longitude) - radians(:longitude))
+ sin(radians(:latitude))
* sin(radians(l.latitude)))) <= :distance공간 인덱스 SQL
SELECT * FROM Location AS l
WHERE ST_CONTAINS(ST_Buffer(ST_SetSRID(ST_MakePoint(:longitude, :latitude), 4326), :distance), l.coordinate);SQL을 설명하자면, ST_Buffer를 이용해 이 지점 주변으로 지정된 거리(:distance)만큼의 영역을 생성하고(원 형태에 가깝다),ST_CONTAINS로 이 영역이 location 테이블의 coordinate 컬럼에 저장된 위치를 포함하는지를 판단한다.
추가적으로 WGS84 좌표체계를 이용하고 있기 때문에 SRID를 4326으로 설정해주었다.
그렇다면 두 SQL 중 어떤 방법으로 조회해야할까?
선릉역을 기준으로 거리별로 SQL을 실행하면서 성능 비교 실험을 진행하였다.
결과는 아래 표와 같다.
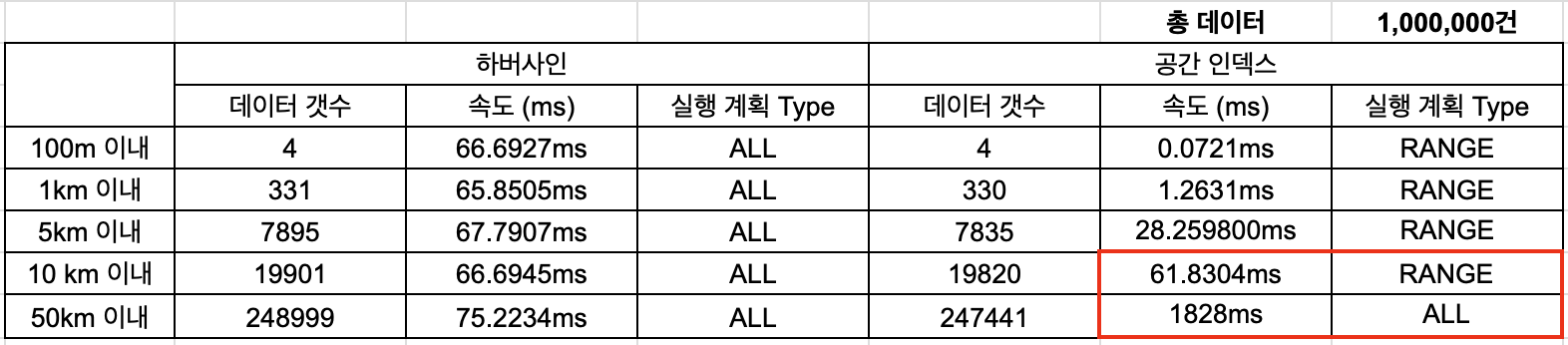
하버사인 공식을 사용한 SQL은 데이터 양에 관계없이 일정한 속도로 결과를 반환했다.
이는 컬럼에 적용된 함수 및 수학적 변환 때문에 쿼리에서 인덱스 활용이 불가능했기 때문이다.
즉, 매번 Table Full Scan을 하기 때문에 조회하는 데이터 범위에 상관없이 항상 일정한 속도를 유지하는 것이다.
100만건의 row를 기준으로 약 66ms의 양호한 처리 시간을 기록하였으나,
데이터 양이 증가함에 따라 처리 시간도 증가할 가능성이 높다.
공간 인덱스를 활용한 SQL은 조회하는 조회하는 거리에 따라 처리 속도가 달라졌다. 거리가 증가함에 따라 속도 차이는 줄어들었고, 50km 이내를 조회할 때는 하버사인 공식보다 24배 느렸다.
100만건의 row 중 1km 이내 조회 시, 하버사인 공식에 비해 하버사인 공식보다 60배 빠르게 처리되었지만,
각 SQL의 정확성을 측정하기 위해, WGS84를 기반으로 거리를 계산하는
빈센티 공식(Vincenty's formula)의 결과와 비교도 진행했다.
10km이내의 하버사인 공식의 오차율은 0.03%, 공간 데이터베이스 함수의 오차율은 0.037%
50km이내의 하버사인 공식의 오차율은 0.05%, 공간 데이터베이스 함수의 오차율은 0.057%로,
대부분의 경우 충분히 허용 가능한 오차 범위였다.
(빈센티 공식보다 더 정확하게 계산하고 싶다면, Karney 공식을 구현한 GeographicLib 라이브러리를 사용하는 것이 가장 효율적이다.)
대부분의 위치 기반 서비스에서는 10km 이내를 한 번에 조회하는 경우가 드물기 때문에,공간 데이터베이스 함수를 사용하는 것이 대체로 더 효율적이다.그러나 서비스의 특성상 거리에 상관없이 일정한 처리 속도를 유지해야 하는 경우,하버사인 공식을 사용하는 것이 유의미할 수 있다.
위 결과는 공간 데이터 함수를 적절하게 사용하지 못했기 때문에 발생한 것으로 보인다.
해당 글을 작성하면서 조사해본 결과, ST_Buffer를 이용해 거리 내의 객체를 조회하는 방식은
일반적으로 거리 기반 조회에 최적화되지 않은 방법이라고 한다.
대신, 거리 기반의 공간 쿼리에 더 적합한 ST_DWithin 함수를 이용하면,
공간 인덱스를 효율적으로 활용하여 성능을 크게 향상시킬 수 있을 것으로 판단된다.
추후 별도의 실험을 진행해 해당 내용을 검증해보겠다.
그리고 고려해야하는 것
위의 내용을 모두 이해했다면, 위치 기반 서비스를 시작하기 위한
기초적인 사전 지식을 어느 정도 갖춘 것으로 볼 수 있다.
이제, 사용자 경험을 개선하는 추가 기능을 고려하는 단계로 넘어가보자.
사용자가 매번 좌표와 주소를 모두 입력하도록 하는 것은 불편하다.
좌표를 입력하면 자동으로 해당하는 주소를 반환하고,
주소를 입력하면 그에 해당하는 좌표를 알려주는
지오코딩과 리버스 지오코딩 기능의 필요성이 느껴질 것이다.
다음 글에서는 지오코딩과 리버스 지오코딩에 대한 더 자세한 내용을 다룰 예정이다.
참고 자료
'Develop > 위치기반 서비스에 도전하는 백엔드 개발자를 위하여' 카테고리의 다른 글
| (2) 백엔드가 위치 기반 서비스 개발하며 알아야할 지오코딩 (0) | 2024.03.12 |
|---|
